This post shares info on Java Messaging System. Java developers are using it in their practice for several reasons. You can read the post and find the reasons.
Why a messaging system?
In the electronics world, data is the actual term used for all information. For which data, “Message” term can be used? Let’s take, a simple scenario if you are registering your details in the web portal, it takes all your information and stores entire data in the relational database which will call as Data. Once you registered successfully, an email functionality triggers, and send an email to you saying that account successfully created. This email event is called as messaging.
In a traditional system, both registering a new user and sending email are tightly couple ex., both are in the same application. This design is extremely responsible, for the system’s performance. Imagine 100s of a user registering in 15 minutes. The same application should focus on creating a new user and sending an email. This process is too costly. To avoid this issue messaging systems come into the picture.
She runs independently and looks for the message and doesn’t care about, where the messages come from. If the message arrives, it consumes the message and sends it to a destination. It is called, loosely coupled and both applications run independently.
The responsibility of Web Portal is to create a new user and to send email to the user is the messaging system’s responsibility. Messaging system is not only used for sending an email. There are many scenarios where we need Messaging system such as notification, a news feed, etc.
There are many messaging systems in the market. RabbitMQ is one of such popular messaging systems in Java, which includes three roles – publisher, subscriber, and queue.
A publisher is the one who sends the message. The sent message will store in temporally in a buffer called a queue. A subscriber is the one who receives the message. These are all players in RabbitMQ, which required for messaging service.
Why we need Apache Kafka?
Since there are more mature messaging systems available in the world, why we need Apache Kafka? That’s a question that triggers the developer’s mind.
The other messaging systems handle only low-volume data. But, Rabbit MQ handles 20K messages per second. Apache Kafka handles 100K messages per second. Kafka provides an easy way to create many Kafka clusters which is called the broker. It is for maintaining load balance. If one broker gets down, the other automatically takes care.
Apache Kafka persists the messages, in hard disk and Java developers can set the lifetime of the message.
Following players are included in the Apache Kafka in the messaging system:
- Topics
- Producer
- Brokers
- Consumer
Topics
Topics hold the stream of messages. For example Topic, “A” can hold the message “Hello World”. If we create a topic, Kafka creates by default one partition. The partition contains a sequence of an index in which messages are getting stored. Based on our requirement we can create many partitions in Topics as in the diagram.
Topic “A”
Partition 1
0 |
1 |
2 |
3 |
4 |
5 |
Partition 2
0 |
1 |
2 |
Partition 3
0 |
1 |
Producer
The producer uses the topics to send messages to the broker.
Consumer
The consumer receives messages from the broker.
Broker
The broker acts as a middleware component for producers and consumers. If the producer sends messages, those messages are maintained in the broker. Consumers consume messages from the broker.
Using Kafka cluster we can create multiple brokers that maintain the messages and load balance. The beauty of the Kafka broker is that it can handle many reads/writes manipulation without any performance tuning.
The entire Kafka cluster runs in Zookeeper.
What is zookeeper?
Zookeeper is an environment that maintains all Kafka broker and their state. If any Kafka broker is down or not available, Zookeeper is liable to notify Consumer/Producer, so Consumer/Producer will start looking into another available Broker.
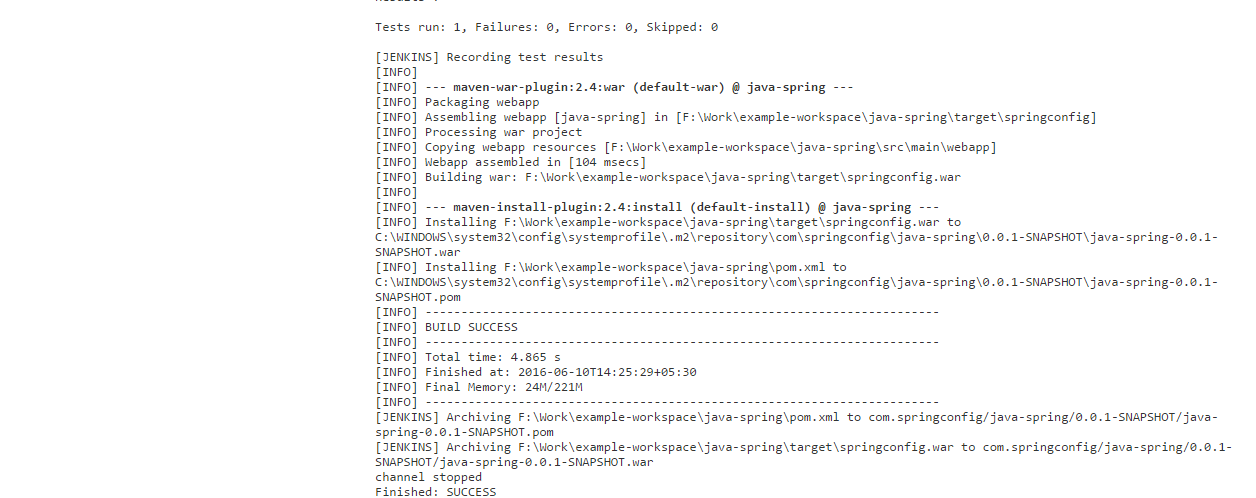
System diagram for Kafka messaging system:
Kafka messaging system environment

Who are Leaders and Followers?
I have already told that we can create many Kafka brokers in which one Kafka broker is the primary broker that handles all manipulation between Producer and Consumer. This Kafka called Leader, and other Kafka brokers are called followers. Due to some situation the leader Kafka is down or shut down for any reason, zookeeper selects a new leader from an available follower, and notifies to Consumer/Producer about the new Kafka leader. Consumer/Producer starts looking into correct Kafka broker.
Kafka messaging system setup
Download zookeeper from following Apache link
http://www.apache.org/dyn/closer.cgi/zookeeper/
After download go to download folder and open conf folder
zookeeper-3.4.6\conf
You can see zoo_sample.cfg
Copy the this file as zoo.cfg
Open zoo.cfg
Change following property with correct path.
Data Dir=<Your path>
Zookeeper store all data in this path
You have done with Zookeeper configuration and this is a time start zookeeper server.
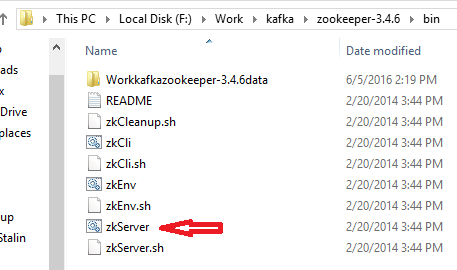
Double click highlighted file(zkServer) to start the zookeeper. You can see following console after starting the Zookeeper successfully.

Now we have configured Zookeeper for your Kafka server.
Download Kafka from following apache link
https://www.apache.org/dyn/closer.cgi?path=/kafka/0.9.0.0/kafka_2.11-0.9.0.0.tgz
Extract the Kafka download folder as in below screenshot.
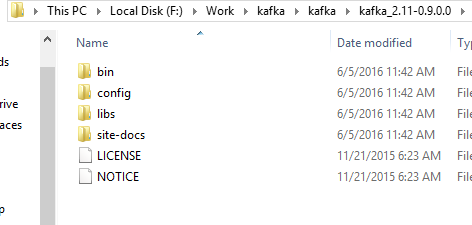
Go to bin folder and apply following command to start Kafka server.
kafka-server-start F:\Work\kafka\kafka\kafka_2.11-0.9.0.0\config\server.properties
This command starts your Kafka server.
If you want to stop kafka server, go to kafka_2.11-0.9.0.0\bin\windows and click kafka-server-stop
If you are using Linux, go to kafka_2.11-0.9.0.0\bin\
Now we have kafka server that is ready to start. Once you started the kafka server, you can see following console

Kafka Producer
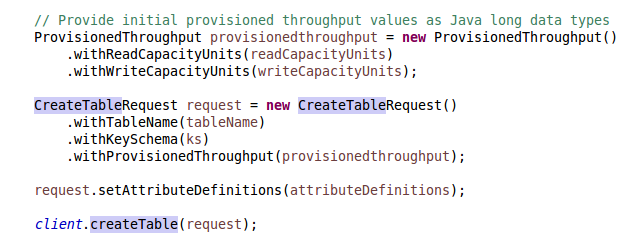
publicclass MyProducer
{
publicstaticvoid main(String[] args) throws Exception{
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String>producer = new KafkaProducer(props);
for(inti = 0; i< 5; i++) {
producer.send(new ProducerRecord<String, String>("test-topic", "Test-Key " + (i+1) ,"Test-Value" + (i+1)));
}
producer.close();
}
}
The above code sets necessary configuration for Kafka producer and creates a new topic called “test-topic” which carries the five different messages. This topic message is sent by producer using producer.send method.
Kafka Consumer
publicstaticvoid main(String[] args) {
//Kafka Consumer configuration
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String>consumer = new KafkaConsumer(props);
consumer.subscribe(Arrays.asList("test-topic"));
while(true){
ConsumerRecords<String, String>records = consumer.poll(100);
for (ConsumerRecord<String, String>record : records)
System.out.println("Partition Offset = " + record.offset() + " Key = " + record.key() + " Value = " + record.value());
}
}
In the above code sets, the necessary configuration for kafka Consumer and receiving messages from a producer. The Producer carries the messages via topic called “test-topic”.
Boostrap.servers
It will start up all available brokers in the kafka
Group.id
We can set group name for multiple consumer. In our case our consumer belongs to test group.
enable.auto.commit
It will commit the offset value based on auto.commit.interval.ms
session.timeout.ms
Using this timeout we can find out any failures in Kafka server.
Key.deserializer and value.deserializer
This is for internal string serialization process for message data.
Acks
This property is having three possible values which are 0, 1, and all. If set 0, a producer doesn’t wait for an acknowledgment. If set 1, producer accepts ack from a leader, if set all, producer accepts ack from all replica i.e. if your Kafka server is having more than 1 broker, it accepts the ack from all (Both leader and follower).
Retries
Number of try for sending messages to Consumer
batch.size
Buffer size for batch size. Let say producer is sending multiple messages to a partition, he will use the batch.size.
buffer.memory
The buffer.memory used by producer for sending messages.
Hope you have understood what Java Messaging System is and why Java developers use it. If you have any question, ask from experts and get answered.